


Em um movimento importante, o Twitter abriu o código por trás do algoritmo de recomendação. Confira os detalhes dessa abertura.
O algoritmo de recomendação do Twitter é projetado para ajudar os usuários a descobrir conteúdo relevante e interessante. Ele usa a inteligência artificial para analisar os tweets que você envia e recebe, bem como as contas que você segue.
Ele também leva em consideração o que outras pessoas estão falando e seu comportamento de seguir e interagir com outras contas.
Com base nessas informações, o algoritmo do Twitter cria uma lista de recomendações personalizadas para você, baseadas em seu interesse e comportamento. Essas recomendações incluem contas para seguir, tweets para ler e outros elementos que você pode achar interessantes.
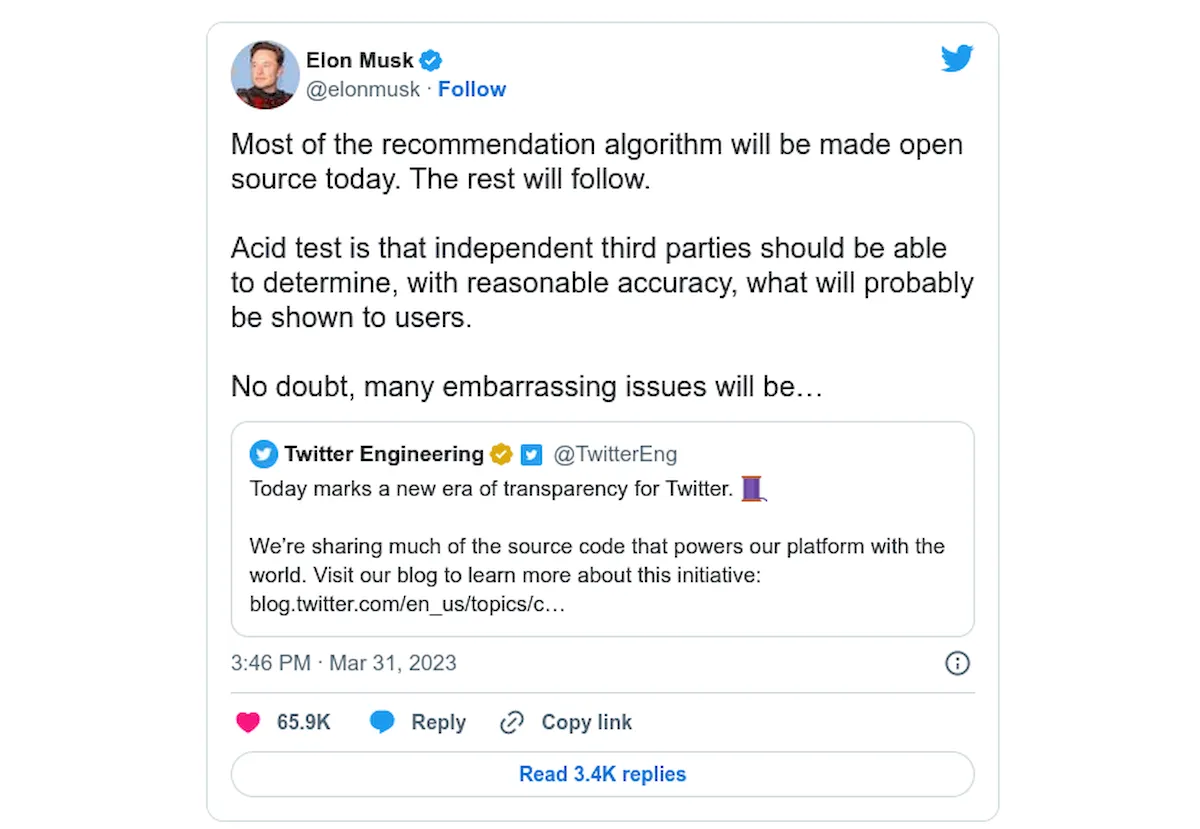
Agora, o Twitter anunciou na última sexta-feira (31/03) que está abrindo o código por trás do algoritmo de recomendação que a plataforma usa para selecionar o conteúdo da linha do tempo For You dos usuários.
Twitter abriu o código por trás do algoritmo de recomendação

No entanto, o código tornado público hoje não inclui partes por trás das recomendações de publicidade ou que colocariam em risco a capacidade do Twitter de manter sob controle as tentativas dos invasores de manipular a plataforma.
“Para esta versão, buscamos o mais alto grau de transparência possível, excluindo qualquer código que comprometa a segurança e a privacidade do usuário ou a capacidade de proteger nossa plataforma de agentes mal-intencionados, inclusive prejudicando nossos esforços no combate à exploração e manipulação sexual infantil.”
“O lançamento de hoje também não inclui o código que alimenta nossas recomendações de anúncios. Também tomamos medidas adicionais para garantir que a segurança e a privacidade do usuário sejam protegidas, incluindo nossa decisão de não liberar dados de treinamento ou pesos de modelo associados ao algoritmo do Twitter neste momento.”
O Twitter publicou dois repositórios GitHub separados contendo o código-fonte de seu algoritmo de recomendação e alguns dos modelos de aprendizado de máquina (ML) que o alimentam.

Como revelou a equipe de engenharia da empresa, os tweets que acabam na linha do tempo For You são escolhidos por um serviço conhecido como Home Mixer, que usa o seguinte pipeline:
- Busque os melhores Tweets de diferentes fontes de recomendação em um processo chamado sourcing de candidatos.
- Classifique cada Tweet usando um modelo de aprendizado de máquina.
- Aplique heurística e filtros, como filtrar Tweets de usuários que você bloqueou, conteúdo NSFW e Tweets que você já viu.
O Twitter explica que:
“Para cada solicitação, tentamos extrair os melhores 1.500 Tweets de um conjunto de centenas de milhões por meio dessas fontes. Encontramos candidatos de pessoas que você segue (dentro da rede) e de pessoas que você não segue (fora da rede)”.
O objetivo final é que a linha do tempo Para você de cada usuário mostre 50% dos tweets relevantes e recentes vindos de seus seguidores e os outros 50% de pessoas que não estão em sua rede com base no que o usuário acharia interessante.
No início deste mês, o Twitter derrubou o código-fonte proprietário e as ferramentas internas vazadas no GitHub e disponíveis publicamente por pelo menos vários meses.
Em um aviso de violação da DMCA, a empresa também pediu ao GitHub que fornecesse informações sobre o histórico de acesso ao código vazado, provavelmente para descobrir quem baixou o código enquanto ele estava disponível online.
O Twitter também está tentando usar uma intimação apresentada ao Tribunal Distrital dos EUA para o Distrito Norte da Califórnia para forçar o GitHub a compartilhar informações de identificação sobre o usuário do FreeSpeechEnthusiasm que publicou os arquivos pela primeira vez e qualquer pessoa que acessou e distribuiu o código-fonte vazado do Twitter, o que poderia provavelmente também será usado para outras ações legais.
O anúncio de hoje segue os tweets do CEO do Twitter, Elon Musk, prometendo tornar o algoritmo do Twitter público.
A primeira é uma enquete (de 24 de março de 2022) que pedia aos usuários que votassem em uma enquete para decidir se o “algoritmo do Twitter deveria ser de código aberto” e a segunda (de 17 de março de 2023) dizia que “o Twitter abrirá o código todo o código usado para recomendar tweets em 31 de março.”

