

Se você quer entender e converter entre representações de permissões unix, conheça e veja como instalar o Concessio no Linux via Flatpak.
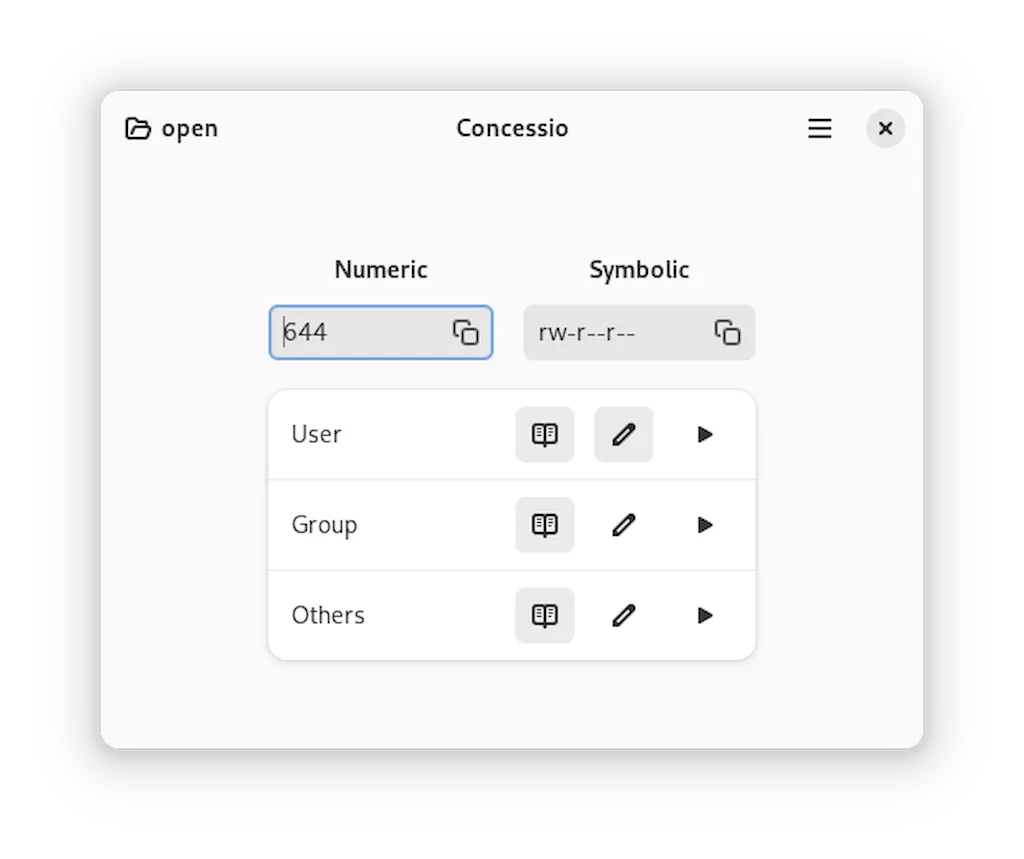

Se você quer entender e converter entre representações de permissões unix, conheça e veja como instalar o Concessio no Linux via Flatpak.

O comando cut no Linux é uma ferramenta essencial para extrair partes específicas de arquivos e textos, permitindo manipular dados por caracteres, bytes ou campos com delimitadores personalizados, e pode ser combinado com outros comandos para otimizar processos no terminal.
Se você já precisou extrair partes específicas de um texto ou arquivo no Linux, sabe que o comando cut é uma ferramenta valiosa. Mas será que você conhece todas as formas práticas de usá-lo para facilitar seu dia a dia no terminal?
O comando cut no Linux é uma ferramenta simples, mas poderosa, usada para extrair partes específicas de linhas em arquivos ou entradas de texto. Ele ajuda a selecionar colunas, caracteres ou bytes de cada linha, tornando a manipulação de dados rápida e fácil no terminal.
Por exemplo, você pode usar o cut para pegar só a primeira palavra de cada linha ou extrair um campo separado por vírgulas em um arquivo CSV.
O comando funciona lendo a entrada, separando por delimitadores, e mostrando apenas as partes desejadas. Por ser prático, o cut é muito útil para quem trabalha com grandes volumes de texto ou arquivos de dados simples.
Não requer instalação, pois já vem presente na maioria dos sistemas Linux. Saber usá-lo facilita o processamento rápido de informações sem precisar abrir editores complexos.
O comando cut permite extrair partes específicas de texto de um arquivo ou entrada. Você pode especificar o que extrair usando diferentes opções, como bytes, caracteres ou campos, e definindo um separador específico (delimitador). Aqui estão as opções comuns:
N-significa da posição N até o fim-Msignifica desde o início até a posição MO comando cut permite extrair informações usando três modos principais: por caracteres, bytes ou campos. Cada modo foca em um tipo diferente de segmento da linha de texto.
Na extração por caracteres, você seleciona posições específicas de letras nas linhas. Por exemplo, cut -c 1-5 pega os primeiros cinco caracteres de cada linha. É útil quando você sabe exatamente onde os dados começam e terminam.
Já a extração por bytes funciona com unidades de dados em nível binário. Com cut -b, você pode cortar partes mesmo se os caracteres tiverem tamanhos diferentes, mas é importante usar isso quando o arquivo não tem caracteres especiais ou codificação complexa.
A extração por campos é a mais usada. Com cut -f, você escolhe colunas separadas por delimitadores, que normalmente são tabulações. Isso ajuda muito na hora de manipular arquivos CSV ou TSV. Por exemplo, cut -f 2 mostra apenas a segunda coluna.
Você também pode combinar o uso de delimitadores com campos para pegar exatamente o que precisa. Essa flexibilidade torna o comando cut ideal para lidar com dados estruturados e extrair partes específicas sem complicação.
O comando cut permite usar delimitadores personalizados para separar os campos no texto. Isso é importante porque nem todo arquivo usa o tab como separador padrão. Muitas vezes, arquivos CSV usam vírgulas, pontos e vírgulas, ou outros caracteres.
Para definir um delimitador diferente, você usa a opção -d seguida do caractere desejado. Por exemplo, cut -d ',' -f 2 pega o segundo campo de uma linha onde os campos são separados por vírgula.
Esse recurso torna o cut muito flexível, pois funciona com vários tipos de arquivos e formatos. Você pode até usar delimitadores raros, como barra ou espaço, conforme sua necessidade.
Além disso, combinar o delimitador personalizado com a seleção de campos permite extrair dados específicos facilmente. Isso evita que você precise abrir o arquivo em um editor para buscar a informação.
Por fim, usar delimitadores personalizados é essencial para manipular dados em scripts e automatizar tarefas no Linux com eficiência.
O comando cut oferece a opção --complement para excluir campos ou caracteres ao invés de selecioná-los. Isso significa que você pode mostrar todas as partes da linha, exceto as que especificou.
Por exemplo, se você quer pegar tudo, menos a primeira coluna, pode usar cut -f 1 --complement. Isso facilita quando você sabe o que quer remover, em vez de listar tudo que quer manter.
Essa opção funciona para caracteres, bytes e campos delimitados. Ela é útil quando há muitos campos e fica difícil listar cada um que deseja manter.
Além disso, o uso de --complement ajuda a criar comandos mais simples e limpos para manipular textos e dados no Linux. Assim, fica mais fácil evitar partes irrelevantes sem complicação.
Lembre-se de sempre combinar essa opção com o tipo de seleção que quer usar, seja por campo, caractere ou byte, para obter o resultado desejado.
O comando cut fica ainda mais poderoso quando você combina ele com outros comandos Linux. Isso permite criar fluxos rápidos e eficientes para processar dados.
Um uso comum é com o comando grep, que filtra linhas com texto específico. Você pode filtrar dados com grep e depois usar cut para extrair partes importantes dessas linhas.
Outra combinação popular é com sort, que ordena dados. Depois de extrair campos com cut, você pode ordenar as informações para análise ou relatórios.
O pipe | é usado para passar a saída de um comando como entrada para o outro. Por exemplo, grep 'erro' arquivo.log | cut -f 2 mostra a segunda coluna das linhas que contêm “erro”.
Também dá para usar com awk e sed, ferramentas que ajudam a editar e formatar texto de formas detalhadas. Assim, o cut complementa esses comandos para extrair dados específicos rapidamente.
O comando cut é uma ferramenta simples e eficiente para extrair dados em sistemas Linux. Seu uso combinado com outros comandos torna a manipulação de texto rápida e prática. Aprender a aplicar opções como delimitadores personalizados e o complement aumenta ainda mais a flexibilidade do cut. Dominar essas técnicas facilita o trabalho com arquivos e fluxos de dados, tornando tarefas do dia a dia mais ágeis. Experimente usar o cut em seus projetos e descubra como ele pode melhorar sua produtividade no terminal.
O cut é um comando usado para extrair partes específicas de linhas em arquivos ou textos no Linux.
Você pode usar a opção -f junto com -d para selecionar campos delimitados, por exemplo: cut -d ‘,’ -f 2 para pegar o segundo campo separado por vírgula.
Extrair por caracteres seleciona posições de letras, por bytes trabalha com unidades binárias, e por campos seleciona colunas separadas por delimitadores.
Use a opção -d seguida do caractere delimitador, como vírgula, ponto e vírgula ou espaço, para definir o separador desejado.
Ela permite excluir os campos, caracteres ou bytes selecionados, mostrando todos os outros que não foram especificados.
Sim, comandos como grep, sort, awk e sed podem ser combinados com cut para criar processos eficientes de manipulação de dados no terminal.
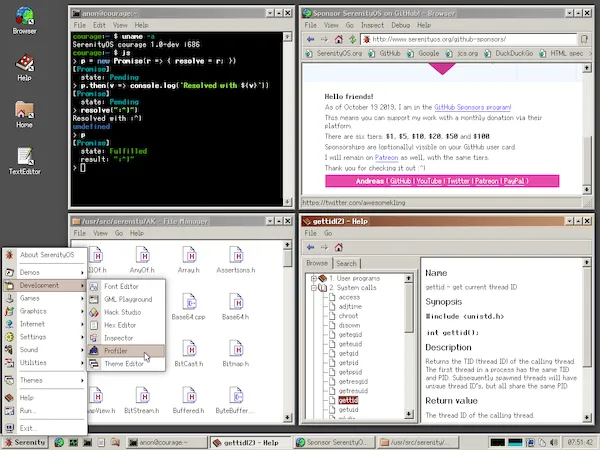
Conheça o SerenityOS, um sistema que oferece uma experiência semelhante à do Unix com uma vibe de computação dos anos 90.

Após muitos percalços, o acordo SCO vs IBM está sendo finalizado, finalmente. Confira os detalhes desse longo processo até agora.

Pesquisadores descobriram uma nova vulnerabilidade que permite que invasores sequestrem conexões VPN no Linux e sistemas Unix. Confira os detalhes dessa nova ameaça!

Se você tem arquivos no formato Matroska (.mkv), então precisa instalar o MKVToolnix para poder manipular esse tipo de arquivo. Por isso, veja como instalar a última versão do MKVToolNix no Linux Ubuntu, Debian, Fedora e openSUSE.

“Atentos ao lançamento da versão 9.04 do Ubuntu, diversos leitores do G1 pediram testes desse novo sistema operacional. Instalei e testei a novidade durante alguns dias e é sobre isso que escreverei nesta coluna. ”
Em mais uma matéria sobre o Ubuntu no site G1, Fernando Panissi fala da nova versão 9.04, fazendo uma passagem pelas novidades que a acompanham. Leitura obrigatória para curiosos e fãs do Ubuntu.
O link para a noticia é este:
http://g1.globo.com/Noticias/Tecnologia/0,,MUL1108916-6174,00.html







