


Se você trabalha com bancos de dados SQL, enteda mais sobre a Otimização de consulta SQL: como ajustar o desempenho de consultas SQL.
Neste artigo, examinaremos como otimizar consultas SQL e melhorar o desempenho da consulta usando dicas e técnicas de otimização de consulta SQL, como planos de execução, índices, curingas e muitos outros.
Otimização de consulta SQL: como ajustar o desempenho de consultas SQL
Quando os negócios e as empresas enfrentam desafios de desempenho do SQL Server, eles geralmente se concentram na aplicação de ferramentas de ajuste de desempenho e técnicas de otimização. Isso ajudará não apenas a analisar e fazer com que as consultas sejam executadas mais rapidamente, mas também a eliminar problemas de desempenho, solucionar problemas de desempenho ruim e evitar qualquer caos ou minimizar o impacto nos bancos de dados do SQL Server.
Noções básicas de otimização de consulta SQL
A otimização de consultas é um processo de definição da maneira e das técnicas mais eficientes e ideais que podem ser usadas para melhorar o desempenho da consulta com base no uso racional de recursos do sistema e métricas de desempenho. O objetivo do ajuste de consulta é encontrar uma maneira de diminuir o tempo de resposta da consulta, evitar o consumo excessivo de recursos e identificar um desempenho de consulta ruim.
No contexto da otimização de consulta, o processamento de consultas identifica como recuperar dados mais rapidamente do SQL Server analisando as etapas de execução da consulta, técnicas de otimização e outras informações sobre a consulta.
12 dicas de otimização de consultas para um melhor desempenho
As métricas de monitoramento podem ser usadas para avaliar o tempo de execução da consulta, detectar falhas de desempenho e mostrar como elas podem ser melhoradas. Por exemplo, eles incluem:
-
Plano de execução: um otimizador de consulta do SQL Server executa a consulta passo a passo, verifica índices para recuperar dados e fornece uma visão geral detalhada das métricas durante a execução da consulta.
-
Estatísticas de entrada/saída: usadas para identificar o número de operações de leitura lógica e física durante a execução da consulta que ajudam os usuários a detectar problemas de capacidade de cache/memória.
-
Cache de buffer: usado para reduzir o uso de memória no servidor.
-
Latência: usada para analisar a duração de consultas ou operações.
-
Índices: usados para acelerar as operações de leitura no SQL Server.
-
Tabelas otimizadas para memória: usadas para armazenar dados de tabela na memória para tornar as operações de leitura e gravação mais rápidas.
Agora, discutiremos as melhores práticas e dicas de ajuste de desempenho do SQL Server que você pode aplicar ao escrever consultas SQL.
Dica 1: Adicionar índices ausentes
Os índices de tabela em bancos de dados ajudam a recuperar informações de forma mais rápida e eficiente.
No SQL Server, quando você executa uma consulta, o otimizador gera um plano de execução. Se ele detectar o índice ausente que pode ser criado para otimizar o desempenho, o plano de execução sugere isso na seção de aviso. Com essa sugestão, ele informa quais colunas o SQL atual deve ser indexado e como o desempenho pode ser melhorado após a conclusão.
Vamos executar o Query Profiler disponível no dbForge Studio para SQL Server para ver como ele funciona.

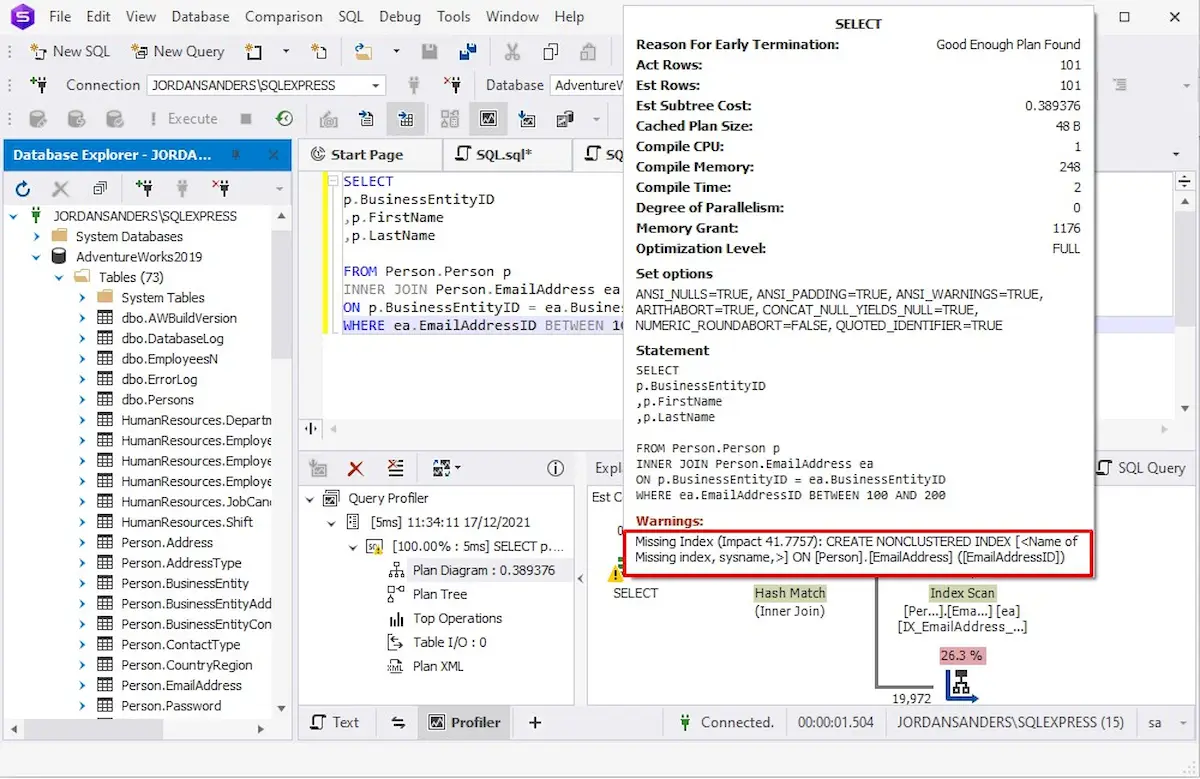
Você também pode entender quais tabelas precisam de índices analisando planos de consulta gráfica. Quanto mais espessa for a seta entre os operadores no plano de execução da consulta, mais dados serão passados. Vendo setas grossas, você precisa pensar em adicionar índices às tabelas que estão sendo processadas para reduzir a quantidade de dados passados pela seta.

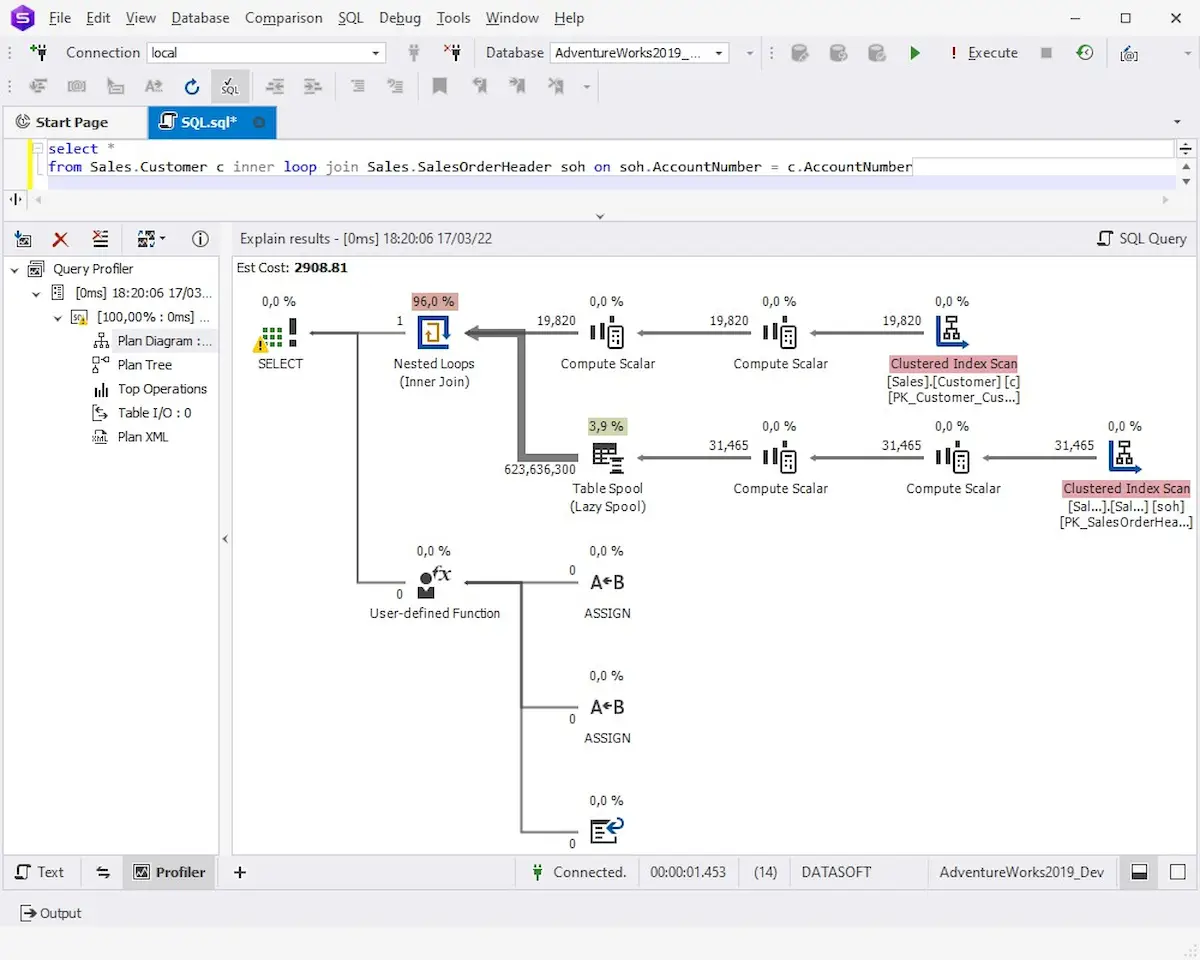
No plano de execução, você pode encontrar o Table Spool (Lazy Spool em nosso caso) que cria uma tabela temporária no tempdb e a preenche de maneira preguiçosa. Simplificando, a tabela é preenchida lendo e armazenando os dados somente quando linhas individuais são exigidas pelo operador pai. O operador Index Spool funciona de maneira semelhante — todas as linhas de entrada são verificadas e uma cópia de cada linha é colocada em um arquivo de spool oculto que é armazenado no banco de dados tempdb e existe apenas durante o tempo de vida da consulta. Depois disso, um índice nas linhas é criado. Tanto o Spool de Tabela quanto o Spool de Índice podem exigir otimização e adição de índices nas tabelas correspondentes.
Loops aninhados também podem precisar de sua atenção. Os Loops Aninhados devem ser indexados, pois eles pegam o primeiro valor da primeira tabela e procuram uma
correspondência na segunda tabela. Sem índices, o SQL Server terá que verificar e processar toda a tabela, o que pode ser demorado e consumir muitos recursos.
Tenha em mente que o índice que falta não garante 100% de melhor desempenho. No SQL Server, você pode usar os seguintes modos de exibição de gerenciamento dinâmico para obter uma visão profunda do uso de índices com base no histórico de execução de consultas:
-
sys.dm_db_missing_index_details: Fornece informações sobre o índice ausente sugerido, exceto para índices espaciais.
-
sys.dm_db_missing_index_columns: Retorna informações sobre as colunas da tabela que não contêm índices.
-
sys.dm_db_missing_index_group_stats: retorna informações resumidas sobre o grupo de índices ausente, como custo da consulta, avg_user_impact (informa quanto desempenho pode ser melhorado aumentando o índice ausente) e algumas outras métricas para medir a eficácia.
-
sys.dm_db_missing_index_groups: fornece informações sobre índices ausentes incluídos em um grupo de índice específico.
Dica 2: Verifique se há índices não utilizados
Você pode encontrar uma situação em que os índices existem, mas não estão sendo usados. Uma das razões para isso pode ser a conversão implícita de tipo de dados. Vamos considerar a seguinte consulta:
SELECT *
FROM TestTable
WHERE IntColumn = ‘1’;
Ao executar essa consulta, o SQL Server executará a conversão de tipo de dados implícito, ou seja, converterá dados int em varchar e executará a comparação somente depois disso. Nesse caso, os índices não serão usados. Como evitar isso? Recomendamos usar a função CAST() que converte um valor de qualquer tipo em um tipo de dados especificado. Veja a consulta abaixo.
SELECT *
FROM TestTable
WHERE IntColumn = CAST(@char AS INT);
Vamos estudar mais um exemplo.
SELECT *
FROM TestTable
WHERE DATEPART(YEAR, SomeMyDate) = ‘2021’;
Nesse caso, a conversão de tipo de dados implícito também ocorrerá e os índices não serão usados. Para evitar isso, podemos otimizar a consulta da seguinte maneira:
SELECT *
FROM TestTable
WHERE SomeDate >= ‘20210101’
AND SomeDate < ‘20220101’
Os índices filtrados também podem afetar o desempenho. Suponhamos que tenhamos um índice na tabela Cliente.
CREATE UNIQUE NONCLUSTERED INDEX IX ON Customer (MembershipCode)
WHERE MembershipCode IS NOT NULL;
O índice não funcionará para a seguinte consulta:
SELECT *
FROM Customer
WHERE MembershipCode = ‘258410’;
Para fazer uso do índice, você precisará otimizar a consulta da seguinte maneira:
SELECT *
FROM Customer
WHERE MembershipCode = ‘258410’
AND MembershipCode IS NOT NULL;
Dica 3: Evite usar vários OR no predicado FILTER
Quando você precisar combinar duas ou mais condições, é recomendável eliminar o uso do operador OR ou dividir a consulta em partes separando expressões de pesquisa. SQL Server não pode processar OU dentro de uma operação. Em vez disso, avalia cada componente da SO que, por sua vez, pode levar a um desempenho ruim.
Vamos considerar a seguinte consulta. SELECIONE *
SELECT *
FROM USER
WHERE Name = @P
OR login = @P;
Se dividirmos essa consulta em duas consultas SELECT e combiná-las usando o operador UNION, o SQL Server poderá fazer uso dos índices e a consulta será otimizada.
SELECT * FROM USER
WHERE Name = @P
UNION
SELECT * FROM USER
WHERE login = @P;
Dica 4: Use curingas apenas no final de uma frase
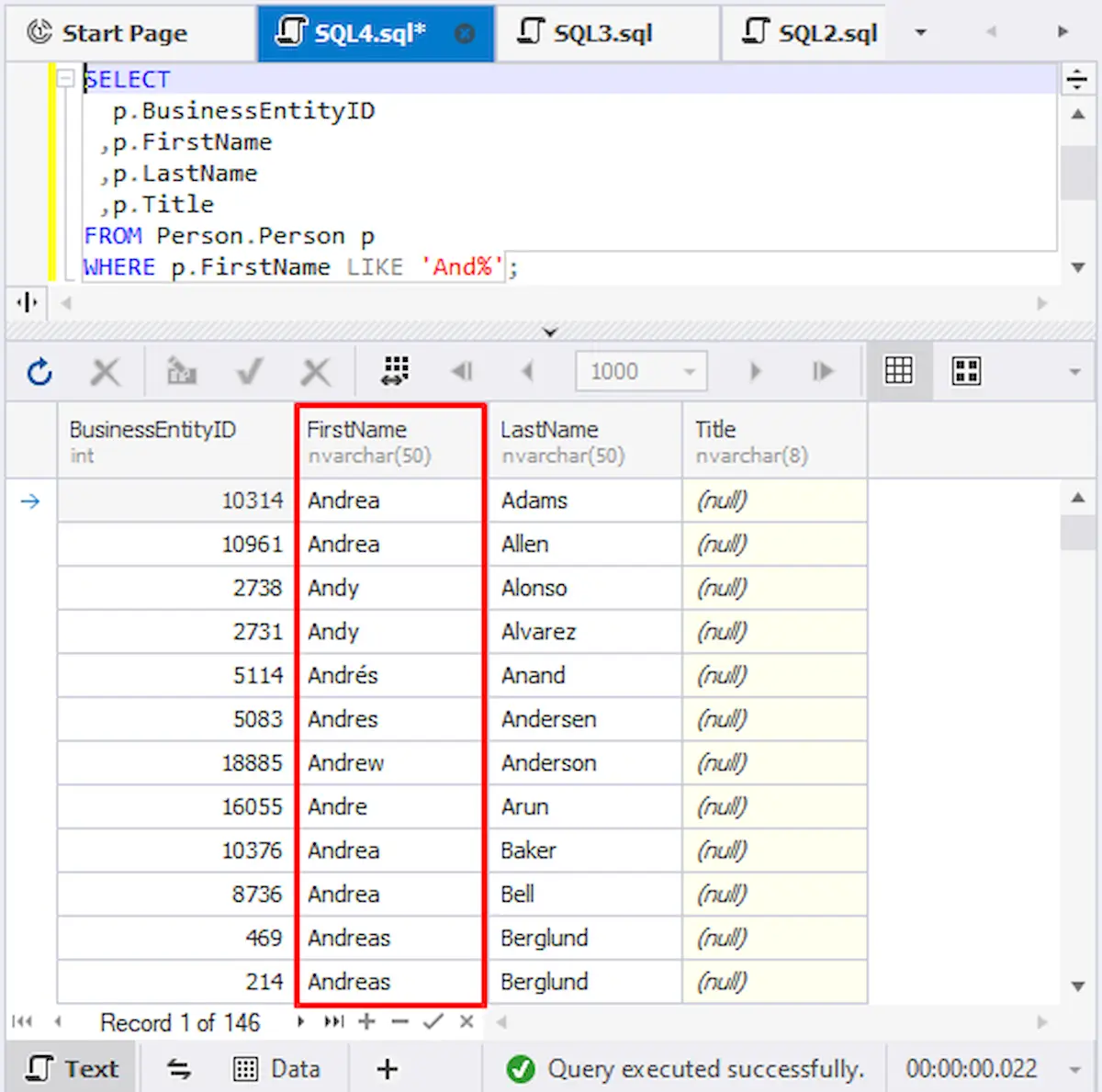
Os curingas no SQL Server funcionam como um espaço reservado para palavras e frases e podem ser adicionados no início/no final delas. Para tornar a recuperação de dados mais rápida e eficiente, você pode usar curingas na instrução SELECT no final de uma frase. Por exemplo:
SELECT
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE ‘And%’;
Como resultado, a consulta recuperará uma lista de clientes cujo Nome corresponde à condição especificada, ou seja, seu Nome começa com ‘E’.

No entanto, você pode encontrar situações em que precisa pesquisar regularmente pelos últimos símbolos de uma palavra, número ou frase — por exemplo, pelos últimos dígitos de um número de telefone. Nesse caso, recomendamos criar uma coluna computada persistente e executar a função REVERSE() nela para facilitar a pesquisa de volta.
CREATE TABLE dbo.Customer (
id INT IDENTITY PRIMARY KEY
,CardNo VARCHAR(128)
,ReversedCardNo AS REVERSE(CardNo) PERSISTED
)
GO
CREATE INDEX ByReversedCardNo ON dbo.Customer (ReversedCardNo)
GO
CREATE INDEX ByCardNo ON dbo.Customer (CardNo)
GO
INSERT INTO dbo.Customer (CardNo)
SELECT
NEWID()
FROM master.dbo.spt_values sv
SELECT TOP 100
*
FROM Customer c
—searching for CardNo that end in 510c
SELECT *
FROM dbo.Customer
WHERE CardNo LIKE ‘%510c’
SELECT
*
FROM dbo.Customer
WHERE ReversedCardNo LIKE REVERSE(‘%510c’)
Dica 5: Evite muitas JUNÇÕES
Quando você adiciona várias tabelas a uma consulta e ingressa nelas, você pode sobrecarregar o servidor. Além disso, um grande número de tabelas para recuperar dados pode resultar em um plano de execução ineficiente. Ao gerar um plano, o otimizador de consulta SQL precisa identificar como as tabelas são unidas, em que ordem e como e quando aplicar filtros e agregação.
Todos os especialistas em SQL estão cientes da importância dos SQL JOINs e entender como usá-los em consultas adequadamente é fundamental. Em particular, a eliminação de JOIN é uma das muitas técnicas para obter planos de consulta eficientes. Você pode dividir uma única consulta em várias consultas separadas que podem ser unidas posteriormente e, assim, remover junções desnecessárias, subconsultas, tabelas, etc.
Dica 6: Evite usar SELECT DISTINCT
O operador SQL DISTINCT é usado para selecionar apenas valores exclusivos da coluna e, assim, eliminar valores duplicados. Tem a seguinte sintaxe:
SELECT DISTINCT column_name FROM table_name;
No entanto, isso pode exigir que a ferramenta processe grandes volumes de dados e, como resultado, faça com que a consulta seja executada lentamente. Geralmente, recomenda-se evitar o uso de SELECT DISTINCT e simplesmente executar a instrução SELECT, mas especificar colunas.
Outra questão é que muitas vezes as pessoas criam JOINs desnecessariamente, e quando os dados dobram, eles adicionam DISTINCT.
Isso acontece principalmente em uma relação líder- seguidor quando as pessoas fazem SELECT DISTINCT… FROM LEADER JOIN FOLLOWER… em vez de fazer o correto SELECT … FROM LEADER WHERE EXISTS (SELECT… FROM FOLLOWER).
Dica 7: Use os campos SELECT em vez de SELECT *
A instrução SELECT é usada para recuperar dados do banco de dados. No caso de grandes bancos de dados, não é recomendável recuperar todos os dados, pois isso exigirá mais recursos na consulta de um grande volume de dados.
Se executarmos a consulta a seguir, recuperaremos todos os dados da tabela Usuários, incluindo, por exemplo, as imagens de avatar dos usuários. A tabela de resultados conterá muitos dados e exigirá muita memória e uso da CPU.
SELECT
*
FROM Users;
Em vez disso, você pode especificar as colunas exatas das quais precisa obter dados, economizando recursos de banco de dados. Nesse caso, o SQL Server recuperará apenas os dados necessários e a consulta terá um custo menor.
Por exemplo:
SELECT
FirstName
,LastName
,Email
,Login
FROM Users;
Se você precisar recuperar esses dados regularmente, por exemplo, para fins de autenticação, recomendamos o uso de índices de cobertura, cuja maior vantagem é que eles contêm todos os campos exigidos pela consulta e podem melhorar significativamente o desempenho da consulta e garantir melhores resultados.
CREATE NONCLUSTERED INDEX IDX_Users_Covering ON Users
INCLUDE (FirstName, LastName, Email, Login)
Dica 8: Use TOP para obter resultados de consulta de exemplo
O comando SELECT TOP é usado para definir um limite no número de registros a serem retornados do banco de dados. Para certificar-se de que sua consulta produzirá o resultado necessário, você pode usar esse comando para buscar várias linhas como um exemplo.
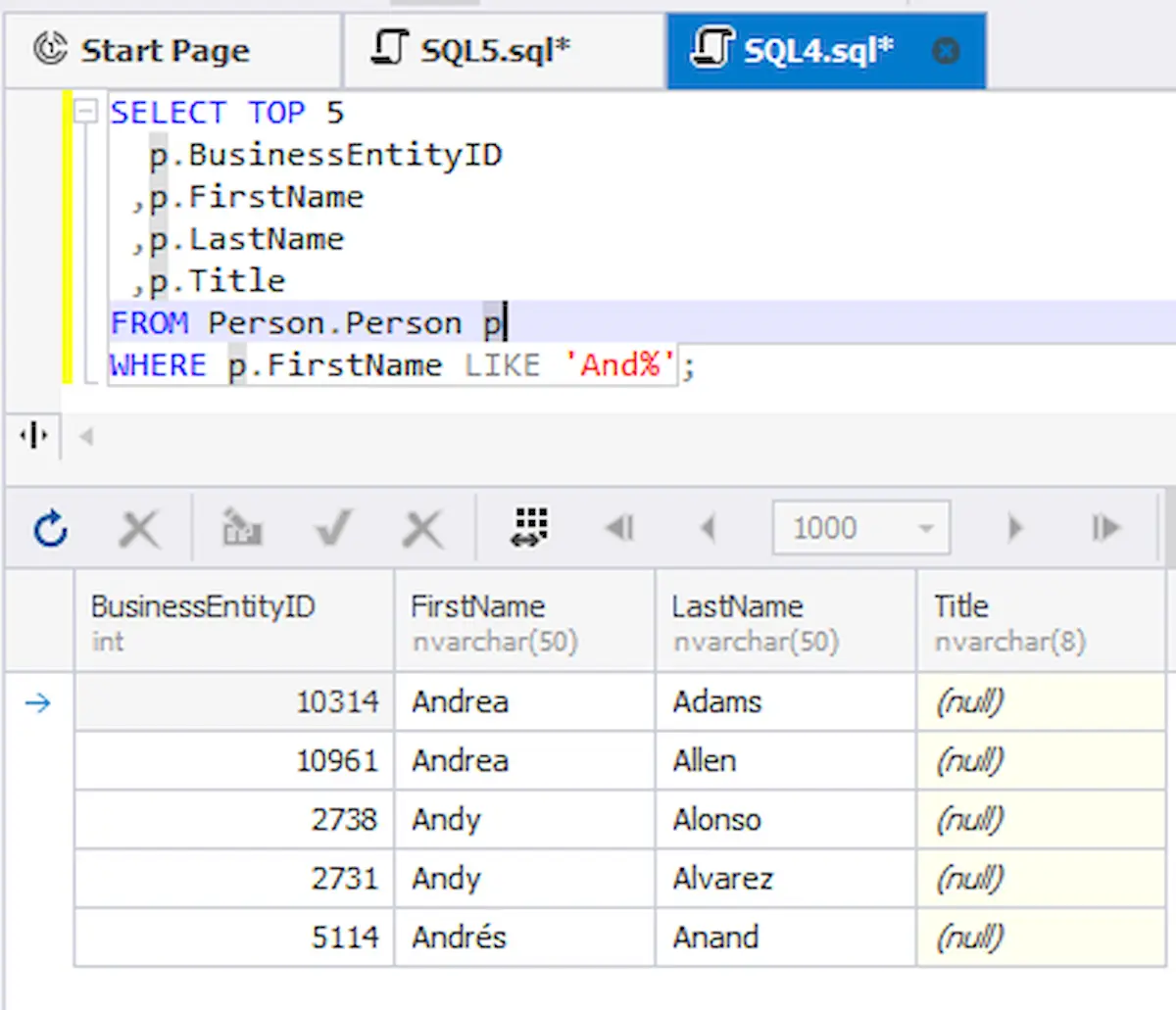
Por exemplo, pegue a consulta da seção anterior e defina o limite de 5 registros no conjunto de resultados.
SELECT TOP 5
p.BusinessEntityID
,p.FirstName
,p.LastName
,p.Title
FROM Person.Person p
WHERE p.FirstName LIKE ‘And%’;
Esta consulta recuperará apenas 5 registros correspondentes à condição:
Dica 9: Executar a consulta fora do horário de pico
Outra técnica de ajuste SQL é agendar a execução da consulta fora do horário de pico, especialmente se você precisar executar várias consultas SELECT de tabelas grandes ou executar consultas complexas com subconsultas aninhadas, consultas de loop, etc. Se você estiver executando uma consulta pesada em um banco de dados, o SQL Server bloqueará as tabelas com as quais você está trabalhando para impedir o uso simultâneo de recursos por transações diferentes. Isso significa que outros usuários não podem trabalhar com essas tabelas. Assim, a execução de consultas pesadas em horários de pico leva não apenas à sobrecarga do servidor, mas também à restrição do acesso de oimageutros usuários a determinadas quantidades de dados. Um dos mecanismos populares para evitar isso é usar a dica WITH (NOLOCK). Ele permite que o usuário recupere os dados sem ser afetado pelos bloqueios. A
maior desvantagem de usar WITH (NOLOCK) é que ele pode resultar em trabalhar com dados sujos. Recomendamos que os usuários deem preferência ao isolamento de instantâneo, que ajuda a evitar o bloqueio de dados usando o controle de versão de linha e garante que cada transação veja um instantâneo consistente do banco de dados.
Dica 10: Minimize o uso de qualquer dica de consulta
Quando você enfrenta problemas de desempenho, você pode usar dicas de consulta para otimizar consultas. Eles são especificados em instruções T-SQL e fazem com que o otimizador selecione o plano de execução com base nessa dica. Normalmente, as dicas de consulta incluem NOLOCK, Optimize For e Recompile. No entanto, você deve considerar cuidadosamente seu uso, porque às vezes eles podem causar efeitos colaterais mais inesperados, impactos indesejáveis ou até mesmo quebrar a lógica de negócios ao tentar resolver o problema. Por exemplo, você escreve código adicional para as dicas que podem ser inaplicáveis ou obsoletas depois de um tempo. Isso significa que você deve sempre monitorar, gerenciar, verificar e manter as dicas atualizadas.
Dica 11: Minimize grandes operações de gravação
Gravar, modificar, excluir ou importar grandes volumes de dados pode afetar o desempenho da consulta e até mesmo bloquear a tabela quando for necessário atualizar e manipular dados, adicionar índices ou verificar restrições a consultas, gatilhos de processamento, etc. Além disso, gravar muitos dados aumentará o tamanho dos arquivos de log. Assim, grandes operações de gravação podem não ser um grande problema de desempenho, mas você deve estar ciente de suas consequências e estar preparado em caso de comportamento inesperado.
Uma das práticas recomendadas para otimizar o desempenho do SQL Server está no uso de grupos de arquivos que permitem espalhar seus dados por vários discos físicos. Assim, várias operações de gravação podem ser processadas simultaneamente e, portanto, muito mais rápido.
A compactação e o particionamento de dados também podem otimizar o desempenho e ajudar a minimizar o custo de grandes operações de gravação.
Dica 12: Crie JOINs com INNER JOIN (não WHERE)
A instrução SQL INNER JOIN retorna todas as linhas correspondentes de tabelas unidas, enquanto a cláusula WHERE filtra as linhas resultantes com base na condição especificada. Recuperando dados de várias tabelas com base na condição de palavra-chave WHERE é chamada de NON-ANSI JOINs, enquanto INNER JOIN pertence a ANSI JOINs.
Não importa para o SQL Server como você escreve a consulta – usando junções ANSI ou NON- ANSI – é apenas muito mais fácil entender e analisar consultas escritas usando junções ANSI.
Você pode ver claramente onde estão as condições JOIN e os filtros WHERE, se você perdeu algum predicado JOIN ou filtro, se você juntou as tabelas necessárias, etc.
Vamos ver como otimizar uma consulta SQL com INNER JOIN em um exemplo específico. Vamos recuperar dados das tabelas HumanResources.Department e HumanResources.EmployeeDepartmentHistory onde DepartmentIDs são os mesmos. Primeiro, execute a instrução SELECT com o tipo INNER JOIN:
SELECT
d.DepartmentID
,d.Name
,d.GroupName
FROM HumanResources.Department d
INNER JOIN HumanResources.EmployeeDepartmentHistory edh
ON d.DepartmentID = edh.DepartmentID
Em seguida, use a cláusula WHERE em vez de INNER JOIN para unir as tabelas na instrução SELECT:
SELECT
d.Name
,d.GroupName
,d.DepartmentID
FROM HumanResources.Department d
,HumanResources.EmployeeDepartmentHistory edh
WHERE d.DepartmentID = edh.DepartmentID
Ambas as consultas produzirão o seguinte resultado:

Práticas recomendadas de otimização de consulta SQL
O ajuste de desempenho do SQL Server e a otimização de consultas SQL são alguns dos principais aspectos para desenvolvedores e administradores de banco de dados. Eles precisam considerar cuidadosamente o uso de operadores específicos, o número de tabelas em uma consulta, o tamanho de uma consulta, seu plano de execução, estatísticas, alocação de recursos e outras métricas de desempenho – tudo isso pode melhorar e ajustar o desempenho da consulta ou piorá-lo.
Para um melhor desempenho da consulta, recomendamos o uso de dicas e técnicas apresentadas no artigo, como executar consultas fora do horário de pico, criar índices, recuperar dados apenas para as colunas específicas, aplicar o filtro, as junções e os operadores corretos, além de tentar não sobrecarregar as consultas.
Além disso, propomos algumas recomendações que podem não estar diretamente relacionadas às técnicas de codificação, mas ainda podem ajudá-lo a escrever código SQL preciso e eficiente.
Usar maiúsculas para palavras-chave
As palavras-chave em SQL geralmente não diferenciam maiúsculas de minúsculas. Você pode usar letras minúsculas, maiúsculas ou ambas mistas em todos os sistemas de gerenciamento de banco de dados populares, incluindo o Microsoft SQL Server. No entanto, recomenda-se usar maiúsculas para palavras-chave para melhorar a legibilidade do código.
Embora alguns desenvolvedores possam achar complicado alternar entre maiúsculas e minúsculas durante a codificação, as ferramentas modernas de formatação de código SQL fornecem a funcionalidade para configurar o uso de maiúsculas e minúsculas, coloração de texto, recuos e outras opções. Essas ferramentas podem aplicar automaticamente a formatação preferida durante a digitação.
Escrever comentários para seu código SQL
Comentar sobre o código é opcional, mas é altamente recomendado. Mesmo que algumas soluções de código pareçam óbvias no momento, o que acontece em alguns meses quando você precisa revisitá-lo, especialmente depois de escrever muitos outros códigos para diferentes módulos ou projetos? Isso é especialmente importante para seus colegas que terão que trabalhar com seu código.
Outro ponto essencial é revisar seus comentários existentes sempre que fizer alterações em seu código, garantindo que eles permaneçam relevantes. Pode levar tempo, mas melhora muito a legibilidade do seu código, e seus esforços compensarão.
Usar um editor de código SQL profissional
Como desenvolvedor, você pode aplicar várias técnicas e personalizar seus fluxos de trabalho de acordo com suas preferências, mas criar código manualmente do zero consome muito tempo e exige precisão excepcional. Um editor SQL confiável e potente facilita a escrita de código e aumenta a precisão.
Os editores SQL modernos oferecem funcionalidade robusta para o desenvolvimento de consultas, como opções de preenchimento automático, bibliotecas de trechos de código, validação de sintaxe e formatação de código. Ferramentas avançadas para desenvolvimento SQL permitem que os desenvolvedores dobrem a velocidade de codificação duas vezes (pelo menos) e garantam excelente qualidade de código.
Conclusão
No artigo, abordamos muitas técnicas de ajuste fino e dicas para melhorar o desempenho. Esperamos que eles trabalhem para você e o ajudem a evitar quaisquer problemas de desempenho que possam surgir.
Além disso, sugerimos que você experimente uma versão de avaliação gratuita e totalmente funcional de 30 dias do dbForge Studio for SQL Server para trabalhar com consultas SQL de forma eficaz.
Assista ao vídeo abaixo para conhecer os poderosos recursos da nossa ferramenta completa de GUI do SQL Server.


