


A recente interrupção do DNS da Cloudflare foi causada por sequestro de BGP, segundo a própria empresa. Confira os detalhes do incidente.
A gigante da Internet Cloudflare relata que seu serviço de resolução de DNS, 1.1.1.1, ficou recentemente inacessível ou degradado para alguns de seus clientes devido a uma combinação de sequestro de Border Gateway Protocol (BGP) e vazamento de rota.
Interrupção do DNS da Cloudflare foi causada por sequestro de BGP


O incidente ocorreu na semana passada e afetou 300 redes em 70 países. Apesar destes números, a empresa afirma que o impacto foi “bastante baixo” e em alguns países os utilizadores nem sequer se aperceberam.
A Cloudflare afirma que às 18h51 UTC do dia 27 de junho, a Eletronet S.A. (AS267613) começou a anunciar o endereço IP 1.1.1.1/32 para seus pares e provedores upstream.

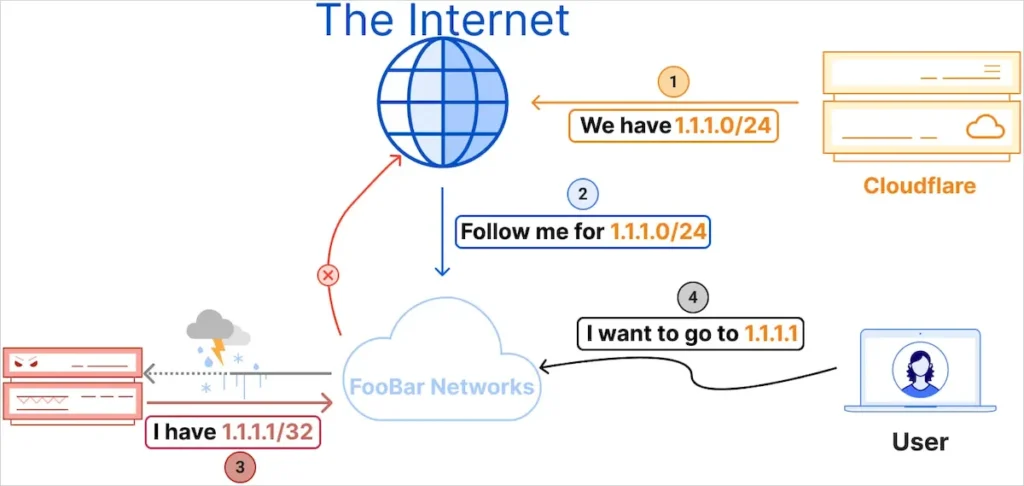
Este anúncio incorreto foi aceito por diversas redes, incluindo um provedor Tier 1, que o tratou como uma rota Remote Triggered Blackhole (RTBH).
O sequestro ocorreu porque o roteamento BGP favorece a rota mais específica. O anúncio do AS267613 de 1.1.1.1/32 foi mais específico do que o 1.1.1.0/24 da Cloudflare, levando as redes a encaminhar incorretamente o tráfego para AS267613.
Consequentemente, o tráfego destinado ao resolvedor DNS 1.1.1.1 da Cloudflare foi bloqueado/rejeitado e, portanto, o serviço ficou indisponível para alguns usuários.
Um minuto depois, às 18h52 UTC, a Nova Rede de Telecomunicações Ltda (AS262504) vazou erroneamente 1.1.1.0/24 upstream para AS1031, o que o propagou ainda mais, afetando o roteamento global.

Esse vazamento alterou os caminhos normais de roteamento do BGP, fazendo com que o tráfego destinado ao 1.1.1.1 fosse mal roteado, agravando o problema de sequestro e causando problemas adicionais de acessibilidade e latência.
A Cloudflare identificou os problemas por volta das 20h UTC e resolveu o sequestro cerca de duas horas depois. O vazamento de rota foi resolvido às 02h28 UTC.
A primeira linha de resposta da Cloudflare foi interagir com as redes envolvidas no incidente e, ao mesmo tempo, desativar sessões de peering com todas as redes problemáticas para mitigar o impacto e evitar a propagação de rotas incorretas.
A empresa explica que os anúncios incorretos não afetaram o roteamento da rede interna devido à adoção da Resource Public Key Infrastructure (RPKI), o que levou à rejeição automática das rotas inválidas.
As soluções de longo prazo que a Cloudflare apresentou em seu artigo post-mortem incluem:
- Melhore os sistemas de detecção de vazamentos de rotas incorporando mais fontes de dados e integrando pontos de dados em tempo real.
- Promover a adoção da Infraestrutura de Chave Pública de Recursos (RPKI) para Validação de Origem de Rota (ROV).
- Promover a adoção dos princípios das Normas Mutuamente Acordadas para Segurança de Roteamento (MANRS), que incluem a rejeição de comprimentos de prefixo inválidos e a implementação de mecanismos de filtragem robustos.
- Incentive as redes a rejeitar prefixos IPv4 maiores que /24 na Default-Free Zone (DFZ).
- Defensor da implantação de objetos ASPA (atualmente elaborados pela IETF), que são usados para validar o caminho AS em anúncios BGP.
- Explore o potencial de implementar RFC9234 e Autorização de Origem de Descarte (DOA).